Computer scientist Maya Gokhale is optimistic about exascale computing’s fast, bright future. But to achieve this success, the Lawrence Livermore National Laboratory researcher and her colleagues focus on an exascale computer’s inevitable failures, from processor cores, to memory and communications links – the unprecedented millions of hardware parts. The failure of any one of these elements could hobble a 1018 floating-point-operation scientific calculation.
“Failure will be a constant companion in exascale computing,” says Gokhale, a 30-year veteran in thinking about the silicon edge of high-performance computing (HPC). “We expect applications will have to function in an environment of near-continual failure: something, somewhere in the machine will always be malfunctioning, either temporarily, or simply breaking.”
Yet just as the most successful entrepreneurs learn and grow from overcoming failure, HPC scientists like Gokhale believe planning for breakdowns at the exascale will not only improve scientific computing; it may be a tipping point toward a new paradigm in how supercomputers are programmed.
As part of its effort to outsmart faults at the exascale, the DOE Office of Science is looking to FOX – the Fault-Oblivious eXtreme-scale execution environment project.
Led by Gokhale, FOX is an ambitious project, now in the last of its three years, with a transformational vision. To succeed at the exascale, FOX’s creators believe, HPC must fundamentally change its approach to failure – from one of seeking hardware perfection at all costs to one of embracing hardware failure when designing a new generation of operating systems.
It’s time to give the job of dealing with faults to a new breed of operating systems.
With 100 million to a billion processing cores spread among millions of nodes, an exascale supercomputer will represent an unprecedented opportunity for scientific computing. But it also will spawn a new frontier in terms of failure rates.
Although the projected hardware failure rate in an exascale machine is still a subject of intense debate, in 2011 the DOE Advanced Scientific Computing Advisory Committee identified exascale resilience (the ability to deal with such faults) “as a black swan – the most difficult, under-addressed issue facing HPC.”
What makes it difficult is that there’s an HPC community consensus that traditional failure-avoidance strategies themselves break down at the exascale.
“The underlying assumption with supercomputers as they’re operated today is that either the machine is perfect or you just reset,” says Ron Minnich, a computer scientist now at Google, who initiated the FOX research program while at Sandia National Laboratories. “As an engineering accomplishment this near perfection is really incredible, but if we think about scaling up, it’s hard to see how that assumption can be sustained either technically or in terms of costs.”
The problem is that to avoid data loss to a system shutdown, today’s largest computers operate on the same approach to hardware glitches as personal computers: If there’s a significant error, the system shuts down, and you reboot it. This is called defensive checkpointing, routinely pausing a computation to save data from all nodes back to a parallel file system. It’s the equivalent of everyone in a Fortune 500 company stopping work to back up their hard drives simultaneously onto a common drive, then going back to work.
One estimate suggests that regular checkpointing, which requires 30 minutes to restart a computation, would slow an exascale machine to less than half its projected efficiency.
“We know that with defensive checkpointing,” Gokhale says, “given the expected fault rates, you could spend all of your time checkpointing and getting no work done, so we absolutely have to have something different.”
That something different encompasses an evolutionary approach toward working with, rather than against, faults.
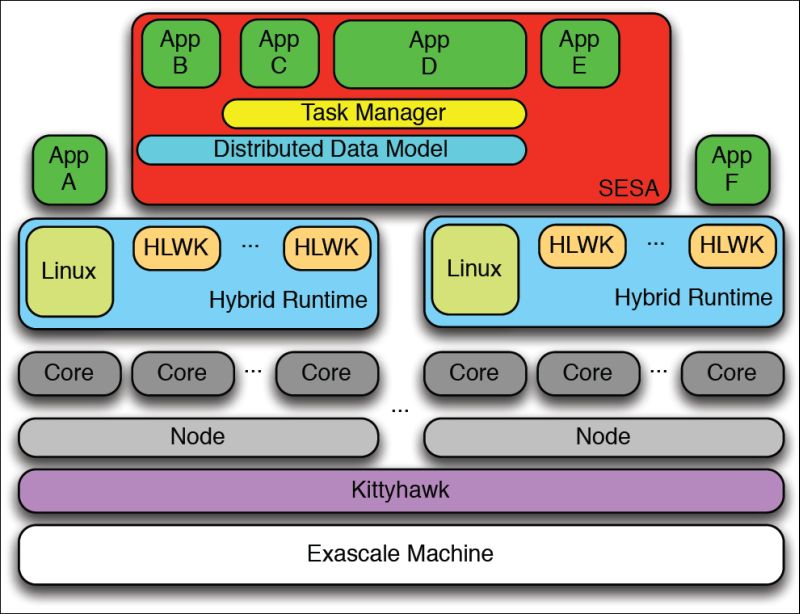
Rather than perfection, FOX achieves its objectives through adaptability, Gokhale says. It’s a fault-tolerant approach that grows out of three primary intertwined innovations: core specialization, a distributed data store and a fault-aware task management approach.
What ties these together is a fundamental shift in the software responsible for dealing with faults – moving from a specific application to a fault-oblivious operating system, like FOX.
“What we’re envisioning with fault-oblivious computing is that the application wouldn’t know about it,” Gokhale explains, “and the application wouldn’t be responsible for saving data periodically, or recovering data.”
A fault-oblivious approach to HPC would be a major about-turn. Today, on supercomputers such as Intrepid, Argonne National Laboratory’s Blue Gene/P, the operating system starts a run and then essentially disappears, handing over control to the scientific application.
“The effort in HPC for the past 20 years has been operating system bypass,” Minnich says. “That’s just another way of saying the operating system can’t do a good enough job, and we have to let the application do the job of moving the data.”
Past weaknesses in HPC operating systems, he adds, spurred the move away from them. However, at the exascale, Minnich says, it’s time to give the job of dealing with faults to a new breed of operating systems.
Getting there won’t be easy. The FOX project to date is an amalgam of software systems, all of which together create a prototype fault-oblivious computing environment.
To tie the pieces together and test its approach, the research team is using an allotment of 10 million processor hours on Intrepid, awarded through DOE’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program.
One of FOX’s key elements is TASCEL, a middleware task management library developed by a team, led by scientist Sriram Krishnamoorthy, at DOE’s Pacific Northwest National Laboratory. With TASCEL, all of a computation’s task queues are stored in a shared memory location. Thus, if a computing node fails, its current task queue can be recovered and reassigned to another node.
“We also have middleware and libraries that keep a consistent data store,” Gokhale says. “We don’t get rid of the task until the work of the task has been completed and stored in the data store. In case of node failure, the replicated task queues and data storage are automatically rebalanced, and the remaining nodes continue oblivious to the failure.”
The FOX project also employs systems software capable of core and node specialization – of simultaneously running various programs and operating systems on different types of cores and nodes, all in the same exascale machine.
NIX, a prototype operating system Minnich co-developed, efficiently divides cores on multicore processors according to function. Kittyhawk, a cloud environment developed by scientists at Boston University, lets users run different operating systems on different nodes. This has enabled the FOX team to port code to the Blue Gene architecture and run a variety of codes to solve problems.
In the FOX project’s final year, Gokhale says, they’ll speed test their fault-oblivious environment with a massively parallel quantum chemistry program originated at Sandia.
“Quantum chemistry computation is enormously challenging because it’s highly irregular, with some parts requiring an enormous amount of communication,” she says. “This will really put FOX to the test.”
Minnich suggests that the challenge fault-oblivious computing faces is more human than technical. From a programming perspective, it’s as big of a shift as the historic move from vector to massively parallel computing.
Whether or not the future of exascale HPC is fault-tolerant, he says, the FOX project’s approach is part of what’s needed to get there.