It takes big computers to recreate the biggest thing there is – the observable universe – with enough details to help cosmologists understand how it looks and why its expansion is accelerating.
A research team led by Salman Habib and Katrin Heitmann of Argonne National Laboratory is tapping the unprecedented speed of DOE computers to help decipher mysteries of the universe. The team, including scientists at Los Alamos and Lawrence Berkeley national laboratories, uses a software framework that’s run with superb efficiency on these world-class machines.
The researchers have created some of the largest and most detailed simulations yet of how the universe evolved, running on Mira, the Argonne Leadership Computing Facility’s IBM Blue Gene/Q system rated earlier this year as the world’s third fastest. The team’s HACC (Hardware/Hybrid Accelerated Cosmology Code) framework has run on more than a million processor cores. It follows tracer particles representing all the matter in the observable universe as gravity pulls them into clumps and strands of visible galaxies and invisible dark matter over billions of years.
The simulation has put up big numbers in Mira test runs, tracking more than a trillion particles – more than any cosmological simulation yet, the team says – and sustaining a blazing speed of 2.52 petaflops (2.52 quadrillion, or 1015, scientific calculations per second). Besides Mira, the researchers have posted significantly higher performance numbers running HACC on Sequoia, Lawrence Livermore National Laboratory’s new 20 petaflops-capable Blue Gene/Q.
Simulations help cosmologists understand their data by testing cosmological structure formation theories.
The team will reveal the results when it presents the research, “The Universe at Extreme Scale – Multi-Petaflop Sky Simulation on the BG/Q” at the SC12 supercomputing conference on Nov. 14 in Salt Lake City. The project is a finalist for the Gordon Bell Prize, awarded at each year’s conference for outstanding achievement in high-performance computing.

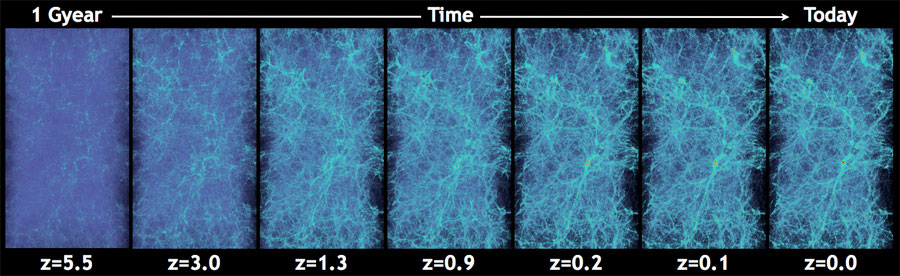
Taken from a simulation of the universe’s evolution, this visualization shows a magnified view of matter distribution. The simulation tracked 8 billion particles in a box of space that is 2.78 billion parsecs (or about 9.1 billion light years) on a side. Each side of the square shown above is 347.2 million parsecs (about 1.13 billion light years) on a side. Each simulation particle is colored based on the corresponding value of the gravitational potential, with red signifying the highest value. Image courtesy of Katrin Heitmann, Argonne National Laboratory.
The team says it expects to improve performance by four times and run at more than 50 percent of theoretical peak speed. Four times the 2.52 petaflops reported for Mira or 50 percent of peak speed on Sequoia would be 10 petaflops plus.
Both Blue Genes still are in acceptance testing, running codes to stress the machines and reveal any flaws before the labs formally sign off on them. HACC also runs as a high-performance test system on Titan, Oak Ridge National Laboratory’s Cray XT5 with a theoretical peak speed exceeding 20 petaflops. The team has carried out science production runs (as opposed to tests) on Hopper, the 1.3 petaflops Cray XE6 at Berkeley Lab’s National Energy Research Scientific Computing Center.
Los Alamos unveiled Roadrunner, the world’s first computer to exceed a petaflops, in 2009. Now, just three years later, HACC has run at least 10 times as fast while Sequoia and Titan have theoretical peak speeds 20 times that of Roadrunner. It’s not just coincidence: HACC is tailor-made to run on Roadrunner and its successors.
Habib, Heitmann and most of the team were based at Los Alamos when engineers were developing Roadrunner. The researchers knew the machine was what Habib calls “kind of a signpost to the future” of supercomputers: a heterogeneous architecture, combining standard AMD-brand CPUs and Sony Cell Broadband Engines – the microchips at the heart of the PlayStation video game console – to boost speed.
“It was a quite difficult machine to program for,” Habib says, and the team essentially wrote a code to fit it. “The idea was that if we could solve the problem for Roadrunner, we would have a methodology that could take care of any machine we could see coming down the pipe. That was the progenitor of HACC.”
Strictly speaking, HACC is a framework rather than a code, Heitmann says, and was designed from the start to run on any architecture – including heterogeneous architectures. Fundamentally, all cosmos-modeling codes solve for the force of gravity acting on particles in an expanding universe. HACC separates the gravitational force into three regimes – long range, medium range and short range – with optimized solutions for each.
“The long-range forces live on the CPU part of these machines,” Heitmann says. “They’re computed in the same way, independent of the architecture.” The short-range, high-resolution force kernel is switched across systems. On Titan it’s adapted to run on graphics processing units (GPUs), accelerators with their roots in computer gaming. Mira has no accelerators, so the solver is tuned to run on standard processors.
“The outer part of the code, which lives on the CPUs, is always the same, but the short-range kernel can be swapped in and out depending on the architecture,” Heitmann says. “That’s why we believe this is a code or framework for future architectures, because it is relatively easy to adapt.”
Hal Finkel, a 2011 alumnus of the DOE Computational Science Graduate Fellowship (DOE CSGF), helped rewrite the part of the code calculating short-range, high-resolution forces for Mira and helped optimize the code to run well, Heitmann says. The DOE CSGF trains students to apply high-performance computing to different scientific disciplines. Finkel graduated from Yale University with a physics doctorate, but also took classes in computer science and applied mathematics.
The simulations will keep pace with the increasing size and detail of sky surveys looking deeply and widely for galaxy clusters and filaments. Surveys can be optical (like the one planned for the Large Synoptic Survey Telescope), producing images, or spectroscopic (like theupcoming Euclid satellite), calculating redshift as a measure of galaxies’ distances. Radio telescopes also search in wavelengths outside visible light.
Each survey produces a Niagara Falls of data. Simulations help cosmologists understand their data by testing cosmological structure formation theories. Habib says it’s important “to have one big simulation or multiple sets of simulations that can cover these enormous volumes” with a reasonable level of accuracy.
Physicists can only surmise dark matter’s existence from its influence on visible, or baryonic, matter. Given gravity’s strength, galaxies and clusters don’t have enough baryonic matter to stick together, they say; there must be a lot of unseen matter – as much as 25 percent of the total stuff in the universe. (The rest makes up dark energy, a smooth component of space.) That makes dark matter critical to understanding how cosmological structure developed.
In a similar way, physicists postulated the existence of dark energy to explain why the universe appears to be expanding at an accelerating rate. Without a simple model of this energy, which Einstein called the cosmological constant, results from the equations of motion explaining expansion don’t agree with observations.
The visible galaxies “are tracers of mass in the universe, most of which is dark,” Habib says. Physicists say halos of dark matter must envelop galaxies and clusters. The images and animations the group produces show dark matter filaments and clumps that visible matter tracks.
The team’s simulations test different models for how the dark universe formed structures that visible matter falls into. Their results are compared with sky surveys to see how well the models jibe with the distribution of visible matter – galaxies – as we see it today. As supercomputing capacity grows, models track ever more particles – into the multi-trillions – with each standing in for a smaller proportion of the overall mass. That will provide the clearest pictures yet to test against observations.
With HACC demonstrating impressive performance in tests (and with new research improving it even more), the team is itching to get onto Mira and other new machines for simulations directed more toward science goals. They plan to run a suite of around 100 models simulating different conditions. The results will generate probabilities that the chosen conditions led to the structure of today’s universe. “We can compare the theory prediction against observation and infer what is the best-fit model, or maybe we find that none of the models” fit, Habib says.
What’s fit so far, in their research and others’, is the cosmological constant model. “This is, of course, annoying for theorists, because no one likes the cosmological constant,” Habib says. “Everyone would prefer for it to go away and be replaced by something else. But so far it’s worked fine.”