Big data extends far beyond its literal interpretation. It’s more than large volumes of information. It’s also complexity, including new classes of data that stretch the capabilities of existing computers.
In fact, analytical algorithms and computing infrastructures must rapidly evolve to keep pace with big data. “On the science side,” says David Brown, director of the Computational Research Division at Lawrence Berkeley National Laboratory, “it caught us somewhat by surprise.”
Detectors, for example, would improve and provide ever more data, Brown says, “but we didn’t realize that we might have to develop new computational infrastructure to get science out of that data.”
Unfortunately, that reflects a common theme, Brown says. “People often neglect the computational infrastructure when designing things.” Consequently, some big data challenges in basic energy research – such as analyzing information from Berkeley Lab X-ray scattering experiments – must start virtually from zero.
Speed is the key goal of advanced software for X-ray scattering analysis.
A material’s crystalline structure scatters a beam of X-rays in a particular way, depending on the angle of the incident beam and the crystal structure’s orientation. This scattering of X-rays requires two components: the X-ray beam and detectors to create images of the scattered rays. The Advanced Light Source (ALS) at Berkeley Lab provides a wide selection of beams, ranging from infrared light to hard X-rays.
Researchers from all over the world use the facility’s beams, says Alexander Hexemer, ALS experimental systems staff scientist. Most of the work around the ring-shaped accelerator involves energy science – battery materials, fuel cells, organic photovoltaics and more. Scientists also come to study biological materials, such as bones to better understand osteoporosis.
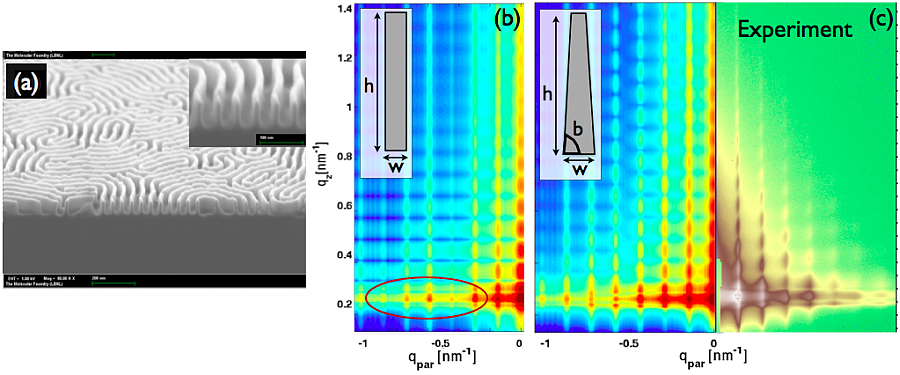
A silicon grating – shown in a scanning electron micrograph (a) – can be modeled with grazing incidence small-angle X-ray scattering algorithms. Assuming a rectangular model of the grating cross-section (b) produces a different simulation of X-ray scattering data than a model based on a trapezoidal cross-section (c, left). The trapezoidal model more accurately simulates the experimental data (c, right). Image courtesy of Tom Russell, University of Massachusetts Amherst, and Alexander Hexemer, Lawrence Berkeley National Laboratory.
These projects promise to keep increasing the flow of data. “We did a survey of the data volume of ALS,” Hexemer says, “and within the next two years, it will be producing 2 petabytes of data a year,” enough to fill 10,000 200-gigabyte computer hard drives. That’s 60 megabytes per second around the clock, 365 days a year.
The volume of data created in X-ray scattering experiments depends, in part, on the detectors, such as Pilatus devices. “These are single-photon counting detectors,” Hexemer explains, that can grab 10 to 300 frames per second, depending on the model.
Such high data-acquisition rates allow scientists to run in situ experiments and study things like how a thin film is created. “Experiments like this are used with organic photovoltaics because no one knows where the crystallization happens,” Hexemer says. “You can collect 90,000 frames of data in two days. That’s about 400 gigabytes of data.”
Scientists have used X-ray-scattering to work with about 20 frames of data, so facing 90,000 seems daunting. The old tools no longer work, Hexemer says. “That’s a big-data problem.”
This means ALS experiments must move to supercomputers – something that requires extensive software revisions. “We have 35 beam lines and each faces different software problems,” Hexemer says. Most of the existing beam-line computational tools were designed to run on single computer processors. “The whole program architecture has to change” to make them run on supercomputers, which employ tens of thousands or hundreds of thousands of processors. Making the transition often means stripping a tool down to only the mathematics of the algorithm and starting from scratch to create the software.
Some of the tools also depend on libraries, such as those available in MATLAB, a numerical computing programming language. “MATLAB works for 10 to 20 frames,” Hexemer says, “but it can’t be adapted for a supercomputer to accommodate the very large volumes and rates.” In such cases, all of the libraries must be redeveloped.
Hexemer and his colleagues have rewritten a few but still have “a zoo of tools that are not converted yet.” Given the expanse of the task, scientists must prioritize, Hexemer says. “You start with tools that are really, really slow and from beam lines that have high data volumes.”
The efforts will pay off. “From a scattering standpoint, having so much more data makes it possible to really understand in situ processes,” Hexemer says. “We will be able to understand any kind of kinetic movements in materials much better than we’ve ever understood them.”
Speed is the key goal of advanced software for X-ray scattering analysis – cutting turnaround from days or weeks down to seconds, says Abhinav Sarje, a Berkeley Lab Computational Research Division postdoctoral researcher.
As an example, Sarje and his colleagues – including Hexemer – worked on an experimental technique called Grazing Incidence Small Angle X-ray Scattering, in which the beam hits the sample at a very low angle, about 0.2 degrees, essentially grazing it.
“When we don’t know the sample’s structure, we have no idea what kind of data we might detect,” Sarje says, so he and his colleagues developed an algorithm that starts with an educated guess about the structure.
Based on that, the algorithm simulates the scattering pattern expected from a beam hitting at a small incidence angle. Researchers compare the simulation with experimental data. Based on the differences, the algorithm makes adjustments in model parameters and runs a new simulation. The comparison runs thousands of times until the images match.
Two pieces are necessary to implement such an algorithm: high-performance code that simulates diffraction patterns and code that improves the suspected structure. Sarje and his colleagues have completed the first piece and now can run simulations in seconds instead of days. Now they’re exploring algorithms for the second piece.
To make this tool available to more users, Sarje and his colleagues are building one version for clusters or supercomputers that use only central processing units and another version for heterogeneous architectures that add graphics processing units.
Eventually, this algorithm will help scientists explore existing materials and develop new ones. The work’s impact could extend from energy to medicine. By running the best algorithms on the fastest architectures, scientists can only imagine the information ahead.